Case study: trusted third parties for market insights
Developed in collaboration with Truata
Context
A retail chain (PriceSavvy) wants to use a dataset held by a different controller (Market Lens) containing information on retail transactions (the market-view dataset). PriceSavvy want to augment their loyalty rewards dataset to calculate the amount spent by their loyalty program members within their market segment, in order to make better marketing decisions.
The table below provides information on the contents of both PriceSavvy’s loyalty rewards dataset and Market Insight’s market-view dataset. Both datasets contain information such as the date, time, location and amount of a transaction.
| Dataset | Dataset information | Held by |
| Market-view dataset | contains transaction information from consumer spending across different merchants, industries, market segments and geographic areas. | Market Lens |
| Loyalty rewards dataset | contains information on transactions across the Retailer’s branch network for which the loyalty members earned loyalty points | PriceSavvy |
PriceSavvy wants to segment their loyalty rewards dataset into groups of customers sharing similar attributes and add information about the total amount spent by similar groups of customers within the target market segment (Figure 1). Spend ‘headroom’ in this instance refers to the additional spend within a retailer’s market segment. This is money that could potentially be spent with the retailer itself.
To comply with the minimisation principle, PriceSavvy decides to carry out the analysis on anonymous data as the analysis does not require personal data.
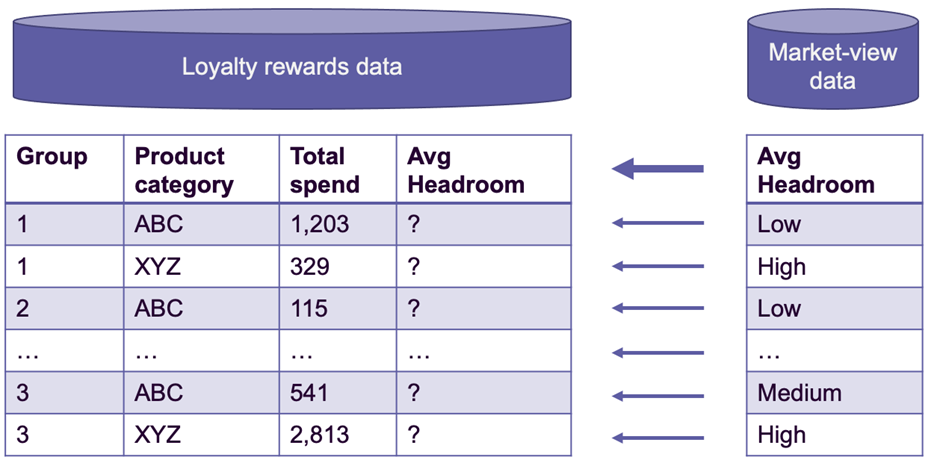
Figure 1: Average headroom from the Market-view dataset is added to similar groups in the loyalty rewards data.
PriceSavvy realises that there is a risk of linkability, as it may be possible to match records in each dataset that relate to the same person, enabling new insights to be learned about them and increasing the risk of re-identification. To reduce this risk, PriceSavvy decides not to attempt to link or join across datasets.
Instead, they decide to:
-
use an independent trusted third party (TTP) as an intermediary to anonymise the two datasets independently of each other;
-
store the resulting anonymised datasets using appropriate technical and organisational measures to ensure the datasets are kept separate and cannot be pooled, joined or merged;
-
dentify groups of interest in both datasets (eg ‘high loyalty’, ‘high frequency, low average transaction value’);
-
calculate the total spend within PriceSavvy’s market segment (the ‘headroom’) for each group of interest identified within the anonymised market-view dataset; and
-
overlay the aggregated k-anonymous group-level headroom information on the groups of interest within PriceSavvy’s dataset.
This approach allows PriceSavvy to generate insights from the aggregated results, which minimises any potential re-identification risk.
Objective
To allow the results of a computation to be shared between each dataset, both datasets were processed to contain the same segment or category labels using a common segmentation method supported by both datasets.
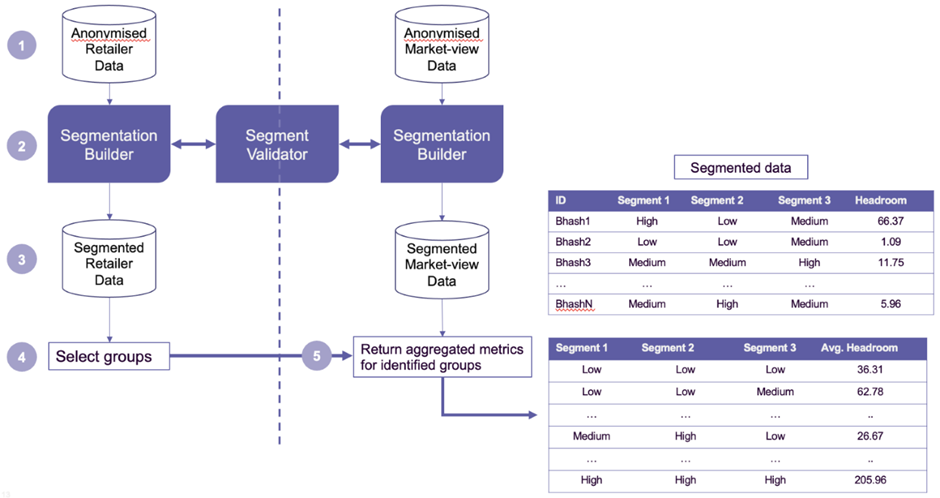
Figure 2: Aggregated insights generated from the retailer dataset are added to the Market-View Dataset
The processing shown in Figure 2 has the following steps:
-
Both datasets are anonymised and stored separately.
-
Relevant segment definitions are validated in each dataset, to find categories of data which are common to each dataset (eg spending frequency, if both dataset have transaction timestamps).
-
Each dataset is segmented using the common segmentation model.
-
Groups of interest are identified within the market-view dataset.
-
Insights for the groups of interest are generated and returned to PriceSavvy.
This approach achieves the required purposes of the processing while using anonymised data.
Technical and organisational measures
The TTP solely determines the means of anonymising the data. In order to ensure the datasets were effectively anonymised prior to processing, the TTP uses technical and organisational measures to reduce identifiability risk to a sufficiently remote level. These measures prevent access to the row-level data used in the processing by any of the participating parties. These measures include role-based access controls and contractual controls to make sure that no re-identification or enhancement of the row-level detail of either dataset can occur via joining or merging. Furthermore, to ensure effective anonymisation, the following steps were also carried out:
- Prior to transfer to the TTP, both Market Insight and PriceSavvy remove or tokenise all known direct identifiers from the source data. They use an appropriate one-way hash function and a secret salt value.
- The TTP performs tokenisation again using a separate secret salt value to further reduce the risk of re-identification.
- PriceSavvy, Market Lens and the TTP all delete the original copies of the datasets so they cannot be matched to the double-hashed versions.
- The TTP performs an identifiability risk assessment of the double-hashed dataset, to find and remove:
- residual direct identifiers (eg phone numbers, credit card numbers, email addresses); and
- indirect identifiers (ie which could be linked back to an original event or person) (eg date, time, location, basket contents and transaction amount).
- The TTP applies further technical measures to fields with the highest level of re-identification risk. The TTP chooses techniques based on type of re-identification risk, the data type and the desired analytical use of the field. For example:
- hashing (SHA256, SHA512) with salt value, if available, facilitates longitudinal analysis;
- format-preserving encryption, preserves a portion of the input value required for analysis with encryption applied to the remainder; and
- other techniques can be applied at this stage include redaction, masking, generalisation, rounding, and noise addition.
- The TTP carries out motivated intruder testing to confirm that people cannot be identified.
- The resulting dataset is stored separately using appropriate technical and organisational measures.
Outcomes
The technical and organisational measures used in the processing ensure that the resulting dataset is effectively anonymised. The use of anonymised data allows PriceSavvy to fulfil their purpose of learning valuable insights from the data, in order to drive forward improved marketing campaigns without using personal data during the analysis.