How do we ensure anonymisation is effective?
-
Due to the Data (Use and Access) Act coming into law on 19 June 2025, this guidance is under review and may be subject to change. The Plans for new and updated guidance page will tell you about which guidance will be updated and when this will happen.
At a glance
- Anonymisation ensures that the risk of identification is sufficiently remote to minimise the risks to people arising from the use of their information.
- Identifiability is a wide concept. A person can be identifiable from many factors that can distinguish them from someone else, not just a name.
- Identifiability exists on a spectrum. When assessing whether someone is identifiable, you should take account of the “means reasonably likely to be used to enable identification”. There are likely to be many borderline cases where you should use careful judgement based on the specific circumstances of the case.
- You do not need to take into account any purely hypothetical or theoretical chance of identifiability, rather, what is reasonably likely relative to the circumstances.
- You should consider both the information itself, and who may get (or want to get) access to it.
- Before you release data to the world at large, you should consider using robust techniques to reduce the higher risk of unauthorised personal data disclosure compared to intentional and controlled data release to known recipients.
- You should also consider potential unauthorised access by people (eg hacking or the actions of rogue employee).
- Applying a “motivated intruder” test is a good starting point to consider identifiability risk.
- You should review your risk assessments and decision-making processes regularly.
In detail
- What should our anonymisation process achieve?
- What is identifiability?
- What are the key indicators of identifiability?
- What is the “spectrum of identifiability”?
- What does data protection law say about assessing identifiability risk?
- How should we approach this assessment?
- What factors should we include?
- Do we need to consider who else may be able to identify people from the data?
- Can we anonymise within our organisation?
- What is the “motivated intruder” test?
- How do we apply the motivated intruder test?
- When should we review our identifiability risk assessments?
- How do we decide when and how to release data?
- What approaches can we take to anonymisation?
What should our anonymisation process achieve?
Anonymisation is about reducing the likelihood of a person being identified or identifiable to a sufficiently remote level. What this looks like depends on a number of factors specific to the context.
It may seem fairly easy to say whether a piece of information relates to an identified person, as this may be clear from the information itself. For example, bank statements clearly identify individual account holders and contain information that relates to them.
It may be less clear whether someone is identifiable. But you should take into account the concept of identifiability in its broadest sense in your anonymisation processes. You should not focus only on removing obvious information that clearly identifies someone.
What is identifiability?
Identifiability is about whether you can distinguish one person from other people with a degree of certainty.
Although a name may be the most common way to identify a person, it is important to understand that the following:
- A person can be identifiable even if you do not know their name. If the information might affect a particular person, even if you don’t know their name or ‘real world’ identity, then they are still identified or identifiable.
- Whether any potential identifier actually means someone is identifiable depends on the context.
Identifiers are pieces of information that can be closely connected to particular people. They can be:
- direct identifiers (eg someone’s name); and
- indirect identifiers (eg a unique identifier you assign to them such as a number).
Data protection law provides a non-exhaustive list of common identifiers in its definition of personal data. For example, name, identification number, location data and online identifier. However, the definition also specifies other factors that can mean a person is identifiable.
Further reading – ICO guidance
See our guidance on ‘What is personal data’ for more information about:
What are the key indicators of identifiability?
You should use two key indicators for determining whether information is personal data or not. These are:
- singling out; and
- linkability.
Effective anonymisation techniques reduce the likelihood of these occurring.
What is singling out?
Singling out means that you can single out the same person across records, or isolate the records that relate to a person from a dataset.
The UK GDPR specifically references singling out as something you should address when you consider the concept of identifiability. You should:
- consider whether singling out is possible, either by you or by another party; and
- make this part of your assessment of the effectiveness of your anonymisation processes.
Even if you do not intend to take action about a person, the fact that they can be singled out may allow you, or others, to do so. This means the person is still identifiable.
For example, if an attacker can isolate the data or link that piece of data to other sources of information, they can use it to single out a particular person and it will not be anonymous.
The risk of singling out depends on contextual factors. For example, information about a person’s year of birth may allow them to be singled out in the context of their family, but not in the context of a different group, such as their class at school. Similarly, someone’s family name may be enough to distinguish them from others in the context of their workplace, but not in the context of the general population (eg Smith or Jones).
Data records with person-level data can still be anonymous, but you should assess the risk of linkability with additional information particularly carefully in these cases.
To determine the possibility of singling out, you should consider:
- the richness of the data and how potentially identifying different categories are; and
- whether you have sufficient technical and organisational measures in place to mitigate this risk.
Example
In the first table, the rows can be differentiated from each other but that does not provide any level of identifiability in itself.
| ID | Birthday month |
|---|---|
| 1 | January |
| 2 | February |
| 3 | March |
| 4 | April |
| 5 | May |
| 6 | June |
In the second table, four records can be isolated from the others as being distinct: records 1 and 4 (isolatable on the basis of age) and record 2 and 3 (isolatable by combining age with location).
| ID | Age | Hospital area | Condition |
|---|---|---|---|
| 1 | 20-29 | Lambeth | COVID-19 |
| 2 | 50-59 | Lambeth | COVID-19 |
| 3 | 50-59 | Southwark | COVID-19 |
| 4 | 60-69 | Lambeth | COVID-19 |
| 5 | 70-79 | Southwark | COVID-19 |
| 6 | 70-79 | Southwark | COVID-19 |
If we assume that this table is from the first week of COVID-19 admissions from a part of South London, it is possible that record 1 provides enough information to single out the person from the database and link to it other information (eg news sources) due to the relative rarity of COVID-19 in younger patients at the start of the pandemic.
Distinguishing one record from others in the table is not sufficient by itself to make the person the record relates to identifiable. In an identifiability assessment, you should also consider what additional data sources are available to:
- narrow down the number people enough to discover someone’s real-world identity; and
- take some action on a person specifically, even if you can’t discover their real-world identity.
What is linkability?
Linkability is the concept of combining multiple records about the same person or group of people. These records may be in a single system or across different systems.
Linkability is sometimes known as the mosaic or jigsaw effect. This is where individual data sources may seem to not be enough to identify someone in isolation, but can lead to the identification of a person if combined.
Simply removing direct identifiers from a dataset is insufficient to ensure effective anonymisation. If it is possible to link someone to information in the dataset that relates to them, then the data is personal data. In some cases, there is a higher risk of anonymous information being combined with other data.
For example, if:
- anonymised data can be combined with publicly available information meaning someone becomes identifiable; or
- complex statistical methods may ‘piece together’ various pieces of information with the same result.
Data that may appear to be stripped of identifiers can still be personal data if it can be combined with other information and linked to a person. For example, data available from social media. Even if stripping identifiers is not sufficient to achieve anonymisation, you must do so to comply with the data minimisation principle (eg if such identifiers are not required).
Common techniques to mitigate linkability include masking and tokenisation of key variables (eg sex, age, occupation, place of residence, country of birth).
Linkability is also the reason that pseudonymous data is still personal data, as the data can be combined with additional information allowing the identification of people it relates to.
Example
In 2006, Netflix published the Netflix Prize dataset. This contained movie ratings of 500,000 subscribers of Netflix that they considered anonymised.
Researchers found that using the Internet Movie Database (IMDB) as the source of additional information, they were able to successfully identify the Netflix records of known users, uncovering their apparent political preferences and other potentially sensitive information.
What about using inferences to learn something new about a person?
An inference refers to the potential to infer, guess or predict details about someone who can already be identified directly or indirectly. In other words, using information from various sources to deduce something new about a person.
Inferences may also be the result of analytical processes intended to find correlations between datasets, and to use these to categorise, profile, or make predictions about people.
An inference can therefore be something you create, as opposed to something that you collect or observe.
Whether an inference is personal data depends on whether it relates to an identified or identifiable person.
To determine the likelihood of learning new information about a person through inference, you should consider the possibility of deducing new information about an identifiable person from:
- incomplete datasets (eg, where some of the identifying information has been removed or generalised);
- pieces of information in the same dataset that are not obviously or directly linked; or
- other information that you either possess or may reasonably be expected to obtain (eg publicly available additional information, such as census data).
You should also consider whether the specific knowledge of others, such as doctors, family members, friends and colleagues, is sufficient additional information to allow inferences to be drawn and linked to an identifiable person.
Example
In the UK, property purchase prices are publicly available. A person purchases a house for £500,000. Data analysis may show a high correlation between the house purchase price and the homeowner's income. A third party, knowing the purchase price of this house, may infer that the homeowner's income is around £100,000 per year. As this inferred income is linked to the homeowner, it becomes personal data, even if the actual income of the homeowner is different.
What is the “spectrum of identifiability”?
In one sense, data protection law presents a simple binary outcome – information in a particular person’s hands either meets the definition of personal data or it does not.
However in practice, identifiability can be highly context-specific. Different types of information have different levels of identifiability risk depending on the circumstances in which you, or another party, processes them.
Whether something is personal data or anonymous information in the hands of a given person is therefore an outcome of assessing identifiability risk, taking into account the relevant facts.
In practice, identifiability may be viewed as a spectrum that includes the binary outcomes at either end, with a blurred band in between:
- at one end, information relates to directly identified or identifiable people (and will always be personal data); and
- at the other end, it is impossible for the person processing the information to reliably relate information to an identified or identifiable person. This information is anonymous in that person’s hands.
For everything in between, identifiability depends on the specific circumstances and risks posed. Circumstances of the processing may change, for example:
- the state of the art for anonymisation techniques changes;
- technical controls or identification attacks change;
- the means reasonably likely to identify someone becomes feasible and cost-effective; or
- data that enables identification becomes available.
Information may ‘move’ along the spectrum of identifiability to the point that data protection law starts to apply to it, or stops applying to it. We provide one way of visualising the spectrum of identifiability below.
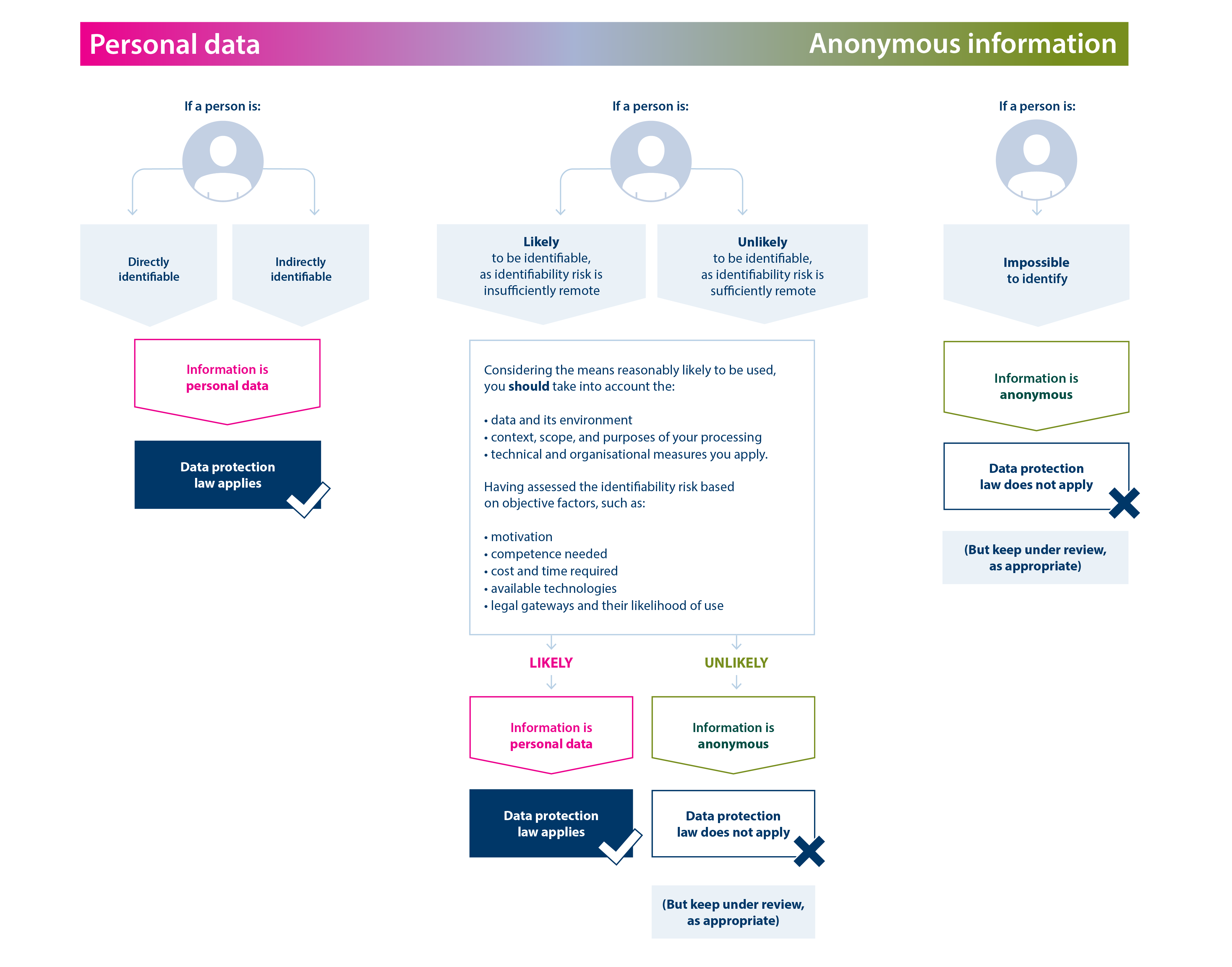
Figure 1: Mapping the concept of the spectrum of identifiability to data protection law
A text description of this diagram is available.
Information may shift towards one end of the spectrum, depending on factors including:
- the specifics of the data. For example, the sensitivity of the variables in the original dataset and the techniques you use to reduce the identifiability of people in the data;
- the context of the processing. For example, who you share the dataset with;
- the availability of any other information in the public domain at a given point in time that may allow for identification of people;
- the data environments involved. For example, the technical and organisational measures in place to control access to the data; and
- your risk management process. For example, how you identify and mitigate any risks of the processing.
Other resources
Some examples of visualising the concept of the spectrum of identifiability include:
- Understanding Patient Data’s ‘Identifiability Demystified’ briefing (external link, PDF);
- the Future of Privacy Forum’s ‘Visual guide to practical data deidentification’ (external link, PDF);
- the National Institute of Standards and Technology (NIST) publication ‘De-Identification of Personal Information’ (NISTIR 8053) (external link, PDF); and
- Privacy Analytics’ presentation ‘Principles of de-identification’ (external link, PDF).
We are using these examples to illustrate different approaches and are not giving them an ICO endorsement.
What does data protection law say about assessing identifiability risk?
When you assess identifiability risk, the first question you should ask is whether the information is personal data in your hands. For example, the data may obviously relate to living people, or you may determine that you have means that are ‘reasonably likely’ to be used to identify people.
If the information is not personal data in your hands, then you should consider whether there are means that are ‘reasonably likely’ to be used by other people. For example, anyone who might obtain access to the information. We refer to this as the ‘reasonably likely’ test. The UK GDPR provides additional information about the factors you should take into account when determining this. Similar considerations apply to Parts 3 and 4 of the DPA 2018.
Recital 26 of the UK GDPR states that:
“To determine whether a natural person is identifiable, account should be taken of all the means reasonably likely to be used, such as singling out, either by the controller or by another person to identify the natural person directly or indirectly. To ascertain whether means are reasonably likely to be used to identify the natural person, account should be taken of all objective factors, such as the costs of and the amount of time required for identification, taking into consideration the available technology at the time of the processing and technological developments.”
Therefore, once you take all objective factors into account:
- if there are means ‘reasonably likely’ to be used by you or by anyone who might gain access to the information to identify someone, then the information is personal data; and
- if no means are ‘reasonably likely’ to be used by you or anyone else, then the information is anonymised.
The more feasible and cost-effective a method becomes, the more you should consider it as a means that is reasonably likely to be used.
How should we approach this assessment?
You must be able to demonstrate that disclosing or sharing apparently anonymous information will not lead to an inappropriate disclosure of personal data. Therefore, you must assess the risk of the information being identified.
You should consider the means that is reasonably likely to be used at the earliest stage of your anonymisation process, even if you don’t intend to identify people. The assessment will be linked to your “release model” (ie public release, release to defined groups, or if anonymising data sets for further internal use only). In all release cases, you should consider the following in your assessment of identifiability:
- whether the information is easily identifiable with readily available means;
- whether there are techniques that enable identification from the information by anyone obtaining access to it;
- whether there is additional information that may enable identification; and
- the extent to which the additional information or techniques are reasonably likely to be used by a particular person to identify people the original information relates to.
Additional information or techniques may be available to different parties, depending on the circumstances. This means that the status of the information may change. For example, the same information may be:
- personal data in your hands. For example, if you also hold additional information that means people are identifiable (even if you hold this separately and apply technical and organisational controls to it); but
- anonymous in the hands of other parties. For example, a specific recipient (or the general public), if they have no access to the additional information and no means reasonably likely to be used to obtain it or identify the people by other means.
Data protection law does not require you to adopt an approach that takes account of every hypothetical or theoretical chance of identifiability. It is not always possible to reduce identifiability risk to a level of zero, and data protection law does not require you to do so.
The key is what is ‘reasonably likely’ relative to the circumstances, not what may be independently ‘conceivably likely’.
Other resources
ISO/IEC 27559:2022 Information security, cybersecurity and privacy protection – Privacy enhancing data de-identification framework provides a framework for identifying and mitigating identification risks.
Anonymeter is a statistical framework to quantify different types of identifiability risks in synthetic tabular datasets. Anonymeter uses attack-based approaches to evaluate the risk of singling out and linkability.
What factors should we include?
You should consider whether identification is technically and legally possible if you intentionally control disclosure to known recipients (rather than unauthorised access). You should take into account objective criteria including:
- how costly identification is in human and economic terms;
- the time required for identification;
- the state of technological development at the time of processing (ie the techniques you use to anonymise the data, or when you share the dataset with another party, or both); and
- technological developments (ie as technology changes over time).
You also should frame this assessment in the context of the specific risks that different types of data release present. These change depending on if you are disclosing information to:
- other parts of your organisation for further internal use only;
- another organisation;
- a pre-defined group of organisations; or
- the wider public or the world at large.
When you disclose, or otherwise make available information, to another organisation, both you and they should assess identifiability risk. You should clearly establish the status the information has in each of your hands.
The greater the likelihood that someone may attempt to identify a person from within a dataset, the more care you should take to ensure anonymisation is effective.
You also should take account of how this risk may change as information moves from one environment to another, depending on what is shared and the controls put in place. Factors that affect the risk of identification include:
- the existence of additional data (eg other databases, personal knowledge, publicly available sources);
- who is involved in the processing and how they interact;
- potential unauthorised access by people (eg hacking or the actions of rogue employee;
- the governance processes that are in place to control how the information is managed (eg who has access to it and for what purposes); and
- the legal considerations that may apply, such as:
- any legal channels which allow additional information to be requested; or
- legal or similar prohibitions that mean while it is possible for information to be technically combined to aid identifiability, doing so is not permitted (eg professional confidentiality and controlled disclosures).
After taking the above into account, if you conclude that the likelihood of identifiability is sufficiently remote, then the information is effectively anonymised. You must:
- document and justify your decision; and
- keep this under review as technologies and the processing change over time.
If you conclude that the likelihood of identifiability is not sufficiently remote, then you are still processing personal data.
You must have appropriate organisational and technical measures in place to process personal data securely (eg pseudonymisation and encryption).
Further reading - ICO guidance
Our guide to data security provides further information on you can comply with the security principle.
Do we need to consider who else may be able to identify people from the data?
Yes. You should consider whether it is reasonably likely that someone else, or someone you are deliberately sharing the information with, can identify people. For example, either from that information, or from that and other information they may possess or obtain.
This can sometimes be known as the ‘whose hands?’ question. This is about the status of the information in the different ‘hands’ of those who process it.
You should note that the ‘whose hands’ approach only applies when disclosing information to an organisation who is not acting with you as a joint controller or as your processor.
For example, if the information is personal data in your hands, it will also be personal data in the hands of any joint controllers, regardless of their technical or contractual ability to identify the people it relates to.
Similarly, a processor only processes personal data on your behalf. This means the status of the data in your hands is what matters.
In these cases, you should use pseudonymisation techniques. This does not affect the status of the data. But it does help you demonstrate the measures you have in place for the security and minimisation principles.
You must take account in your anonymisation processes of the nature, scope, context and purposes of the processing, as well as the risks it poses. These are likely to differ from one organisation to another and from one context to another. Although there may be circumstances where these considerations are similar, you cannot apply one single formula that will guarantee effective anonymisation in all instances.
If you receive data from another controller that they claim is anonymous information, but you are able to re-identify people from the dataset, you must then treat the data as personal data. You must also inform the organisation who provided the data that it is identifiable.
Example: Disclosure between organisations
BankCorp, a large bank, processes extensive customer data, including surveys and transactions, as a controller. FinResearch, an independent UK-based economics research institute, also acts as a controller, using data from various financial institutions for research.
BankCorp creates a dataset to share with FinResearch, ensuring appropriate controls are in place to minimise the risk of identifying people. Both organisations assess the identifiability risk from their own perspective, based on objective criteria, considering how:
- BankCorp creates the dataset; and
- FinResearch will process it.
The assessment determines whether the identifiability risk is sufficiently remote, meaning the dataset is anonymised, or if the risk is not sufficiently remote, meaning it remains personal information. Both organisations document their findings.
These considerations are relevant to BankCorp's decision to disclose the data, despite limited control over FinResearch's data environment or processing circumstances. The key is BankCorp's thorough assessment of identifiability risk.
If the data disclosed is personal information, BankCorp and FinResearch should enter into a data sharing arrangement and follow our data sharing code of practice to ensure they comply with UK GDPR.
If you are disclosing information, you should:
- consider which other organisations are likely to access the information during the initial scoping and design stages;
- ensure that the organisations accessing the information assess the risk of identifiability in their own hands;
- ensure that any other organisation accessing the information has a legitimate reason to do so and only accesses the minimum data needed to achieve their purpose;
- review the technical and organisational controls in place to govern access to the information;
- monitor access to the information and periodically review the data being accessed; and
- consider what other information is available in the public domain to re-identify people as part of your identifiability assessment to determine if the data is anonymous to the world at large.
Can we anonymise within our organisation?
The UK GDPR is mainly concerned with disclosing personal data outside a controller’s own boundaries. However, anonymisation can also be important for safely using or sharing data within organisations, particularly large ones with diverse functions. For example, a retailer might use anonymised data rather than customer purchase records for its stock planning .
If you plan to leverage personal information for further use, then you could either:
- anonymise the information for other purposes; or
- pseudonymise it for the purpose of general analysis.
If you choose to anonymise personal data, you must not retain any additional information within your organisation that would allow identification. For example, the original personal data or other datasets that may be used to re-identify someone. You should put robust technical and organisational measures in place to prevent unauthorised access.
If you need to retain the information that allows for identification, then you are still holding personal data. The dataset is pseudonymised, rather than anonymised.
What is the “motivated intruder” test?
Data protection law does not specify how you determine whether the anonymous information you release is likely to result in the identification of a person.
You must consider all practical steps and means that are reasonably likely to be used by someone motivated to identify people whose personal data was used to derive anonymous information.
This is known as the motivated intruder test. You must use this test to help you to assess the identifiability risk of (apparently) anonymous information.
Both the ICO and the First-tier Tribunal (General Regulatory Chamber), which deals with information rights appeals, use this test.
You should adopt a motivated intruder test as part of your risk assessment. You should also use the test as part of any review, both of your overall risk assessment and the techniques you use to achieve effective anonymisation.
Who is a motivated intruder?
A motivated intruder is someone who wishes to identify a person from the anonymous information that is derived from their personal information. The test assesses whether the motivated intruder is likely to be successful.
You should assume that a motivated intruder is someone that:
- is reasonably competent;
- has access to appropriate resources (eg the internet, libraries, public documents); and
- uses investigative techniques (eg making enquiries with people who may have additional knowledge about a person, or advertising for anyone with that knowledge to come forward).
The intruder is therefore someone who is motivated to access the personal data you hold in order to establish whether it relates to people and, if so, to identify them. Such intruders may intend to use the data in ways that may pose risks to your organisation and the rights and freedoms of people whose data you hold.
You should assess the means that are reasonably likely to be used by a determined person with a particular reason to want to identify people. Intruders may be investigative journalists, estranged partners, stalkers, industrial spies or researchers attempting to demonstrate anonymisation weaknesses. You should consider whether these type of intruders may be reasonably likely to use specialist resources and expertise to achieve identification.
You should also consider:
- their relationship to the person the data relates to;
- their background knowledge;
- whether they are targeting a specific or random person or people in the dataset;
- whether they know (with a degree of certainty) information about that person is in the dataset; and
- the perceived value of the data from the perspective of the motivated intruder.
Depending on the perceived value of the data to them, a motivated intruder may well use specialist knowledge or equipment or resort to criminal acts to gain access to the data and to seek to identify the people it relates to. For example, when assessing financial data, confidential files and other types of high-value data, you should also consider intruders with stronger capabilities, tools and resources.
The intruder can be someone who is not intended to have access to the information, or someone who is permitted access to it.
In essence, your motivated intruder test should consider:
- the nature, type and volume of information you process;
- the likelihood of someone wanting to attempt to identify people, for whatever purpose;
- the range of capabilities an intruder may have;
- the information that they may already have (or can access); and
- the controls you deploy within your data environment to prevent this.
Obvious sources of information that a motivated intruder may use include:
- libraries;
- local council offices;
- church records;
- public records (eg General Register Office, the electoral roll, the Land Registry, the National Archives);
- genealogy websites;
- online services (eg social media, internet searches);
- local and national press archives;
- AI tools, such as generative AI chatbot tools; and
- releases of anonymous information by other organisations (eg public authorities).
You should limit access to data where possible and consider the safeguards that you can adopt to reduce the risk in this case. If the information is still identifiable without appropriate safeguards, then you must put security measures in place to reduce the risk to people.
What types of motivations are there?
Some types of information will be more attractive for a motivated intruder to reidentify than others. Obvious motivations may include:
- finding out personal data about someone else, for malicious reasons or financial gain;
- the possibility of causing mischief by embarrassing others, or to undermine the public support for release of data;
- revealing newsworthy information about public figures;
- political or activist purposes (eg as part of a campaign against a particular organisation or person);
- curiosity (eg a local person’s desire to find out who has been involved in an incident shown on a crime map); or
- a demonstration attack in which a hacker or researcher is interested in showing that identification of people is possible.
You still should undertake a thorough assessment of identifiability risk to determine the potential impact on people even when your data is seemingly ordinary, innocuous or otherwise without value.
Example
A supermarket maintains a database containing shopping histories of their customers. One of the entries includes a series of transactions for a customer who frequently buys products related to a health condition. Although there may be no clear motivation for someone to identify this customer, the potential embarrassment or anxiety if their identity were revealed could be very high.
You should reflect these potential harms in the anonymisation techniques you employ to protect this data.
Who can carry out the motivated intruder test?
You could carry out a motivated intruder test yourself, via a third party, or a combination of both.
If you do the test yourself, you should involve staff with appropriate knowledge and understanding of both your anonymisation techniques and of any other data that could be used for identification.
To determine the likelihood of more complex datasets being matched with publicly available data (eg statistical data), you may require specialist knowledge to help you assess the risk of identification. You could consider an external organisation with experience and expertise of intruder testing or ethical hacking. This can be beneficial, as the external organisation may:
- bring a different perspective to the test (eg that of an independent attacker); and
- be aware of data resources, techniques and types of vulnerability that you may have overlooked or are not aware of.
Does the type of data release matter for the motivated intruder test?
Yes. The type of data release has an impact on the factors you have to consider to assess the identifiability risk and how to ensure anonymisation is robust and effective.
With public release, you should have a very robust approach to anonymisation. This is because when you release information publicly, you lose control of the data. For example, it is almost impossible for you to retract the data if it later becomes clear that it relates to people that are identifiable. You also do not have control over the actions and intentions of anyone who receives that information.
With release to defined groups, you should consider in your identifiability risk assessment what information and technical know-how is available to members of that group. Contractual arrangements and associated technical and organisation controls play a role in the overall assessment. Fewer challenges may arise than with public release.
This is particularly the case if you retain control over who can access the data and the conditions in which they can do so. Designing these access controls appropriately will help reduce identifiability risk and potentially allow you to include more detail, while continuing to ensure effective anonymisation. Data access environments can help you retain control over the information.
You still should consider the possibility that the data may be accessed by an intruder from outside the group, or that it may be shared inappropriately. You should address this with physical and technical security controls aimed at preventing this access. If there is a greater likelihood of accidental release or unauthorised access, you must demonstrate how you mitigate this risk in your identifiability risk assessment.
Further reading – ICO guidance
Using a Trusted third party (TTP) or Trusted Research Environment (TRE) is one way of working with other organisations in a trusted environment.
How do we apply the motivated intruder test?
When considering the motivated intruder test, you should consider the different types of information that may be available.
How does a relationship between a motivated intruder and a person affect the risk of identification?
There are situations where a motivated intruder can already have some background information. Prior knowledge depends on the relationship between the intruder and the person they wish to identify. You should consider the following factors:
- the likelihood of intruders having and using the knowledge to allow identification; and
- the likely consequences of this identification, if any.
Identifiability risk can arise where one person or group knows a great deal about another person. They may be able to determine that 'anonymised' data relates to a particular person, even if another member of the public would be unable to. For example:
- one family member may work out that an indicator on a crime map relates to an incident involving another family member; or
- an employee may work out that a particular absence statistic relates to a colleague who they know is on long-term sick leave.
Certain professionals with prior knowledge (eg doctors, financial advisors) are not likely to be motivated intruders. This can apply if it is clear that their profession imposes confidentiality and ethical conduct rules. You should consider any possible circumstances where people in these professions may be motivated to break these rules (eg for financial gain).
You should not make assumptions about information people have shared with others. For example, teenagers may not share certain medical information with parents or other family members.
How do we assess the risk of identification?
You may find it difficult to assess the likelihood of identifiability in large datasets or collections of information. In these cases, you should consider a more general assessment of the risk of prior knowledge leading to identification.
For example, you could consider the risk of at least one or a few of the people recorded in the information being identified. You should then make a global decision about the likelihood of those who might want to re-identify people seeking out or coming across the relevant data.
The likely consequences can also be difficult to assess in practice. Another person’s sensitivity may differ from yours. For example, the disclosure of the address of a person in a witness protection scheme or someone escaping an abusive relationship will have more impact than the disclosure of the address of an average person.
To help you with this assessment, you could consult representatives of the people whose data you are anonymising, such as trade unions, patient groups or other advocacy groups.
What is the difference between information, established fact and knowledge?
It is also useful to distinguish between recorded information, established fact, and knowledge, when assessing whether a motivated intruder can identify a person from anonymous information.
Example
- “Mr B. Stevens lives at 46 Sandwich Avenue, Stevenham.”
This may be established fact (eg because the information is recorded in an up-to-date copy of the electoral register).
- “I know Mr B. Stevens is currently in hospital, because my neighbour, Mr Stevens' wife, told me so.”
This is personal knowledge, because it is something that Mr Stevens’ neighbour knows.
You should consider recorded information and established fact first. It is easier to establish that particular information is available than to work out whether someone has the knowledge necessary to allow them to identify someone.
Personal knowledge combined with anonymous information can lead to identification. You must have a reasonable basis, rather than just a hypothetical possibility, before you to consider there is a significant risk of identifiability.
What about educated guesses?
You must have a degree of certainty that information is about one person and not another.
The mere possibility of making an educated guess about a person’s identity does not present a data protection risk. Even if a guess based on anonymous information is correct, this does not mean that a disclosure of personal data has happened.
Example
A bike-sharing service releases anonymised data about the total distance travelled by each bike over a certain period. The bike-sharing service adds random noise to the total distance travelled by each bike before releasing the data. This means that the released distances are close to the true totals, but not exactly the same.
The data does not include any information about the specific times the bikes were used or the identities of the people who used the bikes.
Someone knows that a particular person frequently uses the bike-sharing service and tends to travel long distances. They make an educated guess that this person contributed to the high total distance travelled by a certain bike.
However, given that the dataset includes many bikes with similar total distances travelled, it would be nearly impossible to determine with a high degree of certainty that any specific entry in the dataset corresponds to this person.
Therefore, even though they could make an educated guess, it could also be easily disproved by the fact that the data is not unique to that person.
When should we review our identifiability risk assessments?
You should periodically review the decisions you take when anonymising personal data and the assessments that underpin them. The timing and frequency of your review depends on the specifics of the information you anonymise, as well as the circumstances both of its disclosure and its use afterwards.
Example
A researcher submits yearly FOI requests to a public authority. The researcher asks for statistics about the active participants in a programme the authority runs, including by number and characteristics such as age, sex, religious belief and nationality, broken down by quarter.
For three consecutive years the authority provides responses, because it is satisfied that the information is anonymous. Each year it re-assesses the nature of the information to make sure this is still the case.
On the fourth year, the authority withholds the information. Their reassessment led to the conclusion that releasing the information would be likely to lead to people being re-identified. This was because:
- the number of participants in the programme had decreased compared to previous years;
- a high-profile event involving the participants increased the likelihood that there were people motivated to re-identify them; and
- there was more information available in the public domain as a result of media reports and inquiries about the programme.
You should make sure that, as technology changes, you update your original assessment to reflect the impact that change may have on your decision-making.
You should also monitor changes in what data is publicly available as it may mean it becomes easier to re-identify data that you previously considered anonymised. You should consider the duration of the processing and how long the original data will be kept in identifiable form when determining how often to review your identifiability assessments. To do this effectively, you should:
- review highly sensitive data and regularly updated data at more regular intervals than static or infrequently updated data;
- regularly monitor technological developments (eg security best practices) and the effectiveness of anonymisation techniques which may affect the effectiveness of the anonymisation; and
- monitor current and new public data sources (eg reviewing the information available on the Internet or electoral roll).
You should re-assess identification risk under the following circumstances:
- if new attacks or vulnerabilities affect the technical and organisational measures you are using;
- if new datasets are released which may increase the risk of linkability or inferring new personal information related to a person;
- before you grant access to new recipients; or
- if the purposes for the anonymised data changes (eg when it is combined with other datasets).
Other resources
Several existing frameworks are available which can help you systematically consider the motivated intruder test, for example:
- ONS Guidance on intruder testing
- The Anonymisation Decision Making Framework (section 7.4 Penetration tests)
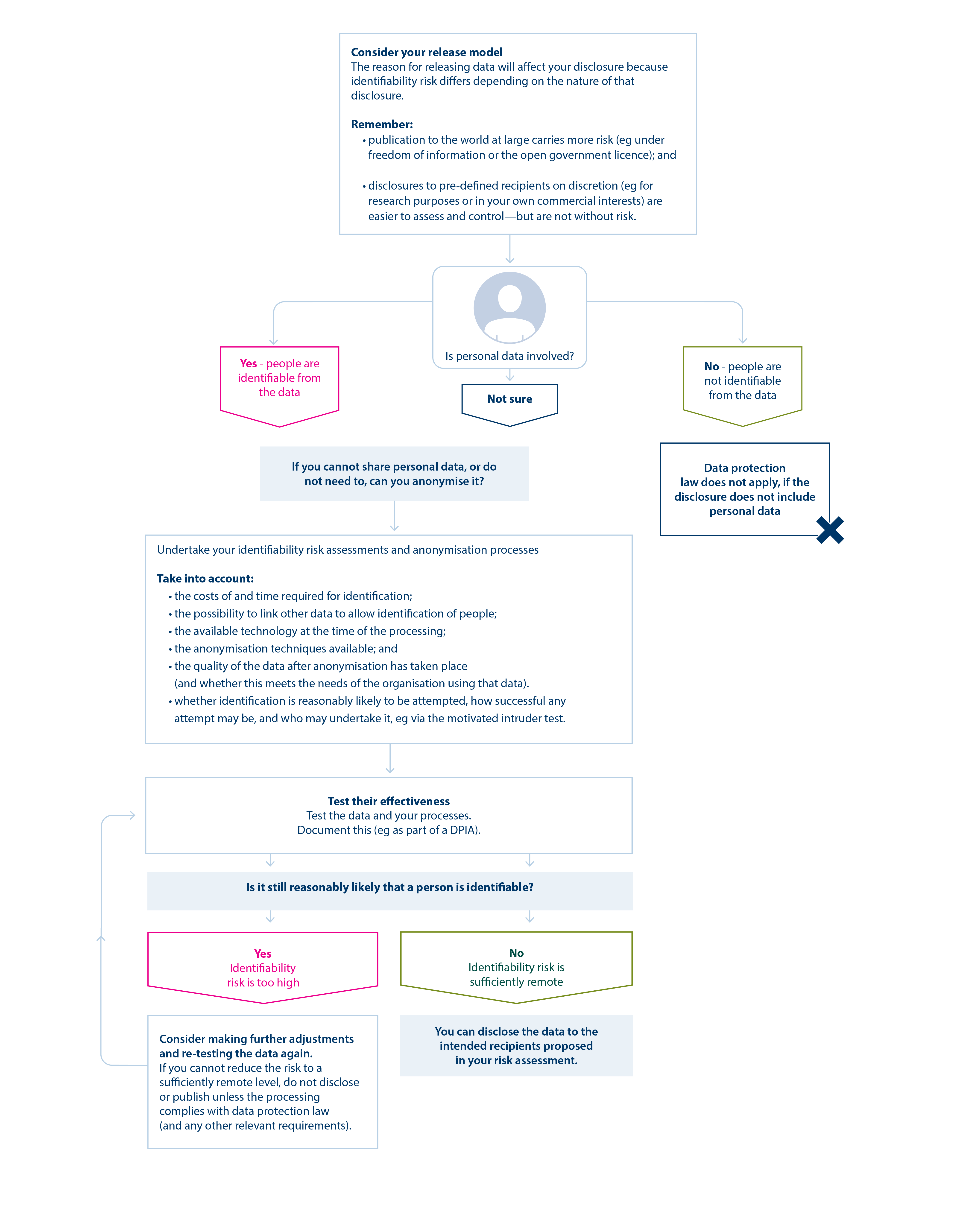
How do we decide when and how to release data?
The considerations in this section of the guidance will help you ensure your assessment of identifiability risk is appropriate for the type of disclosure you undertake.
In summary, you should:
- consider your release model;
- conduct an initial assessment about whether the information includes personal data;
- establish whether you can anonymise that data;
- test the effectiveness of your anonymisation techniques (eg by assessing whether people are still identifiable);
- make further adjustments, as appropriate; and
- document the above, including your decision about the disclosure.
Figure 2 below represents a way that you should implement this process.
Further reading – ICO guidance
Read the section on ‘What accountability and governance measures are needed for anonymisation?’ for further guidance on accountability and governance measures.
What approaches can we take to anonymisation?
There are two main approaches to anonymisation techniques:
- Generalisation, which reduces the specificity of the data. This changes information that may identify someone so that it relates to multiple people. This means members of that group can't be identified or are no longer identifiable.
- Randomisation, which can be used to reduce the certainty that a record relates to a particular person. This changes information that may identify someone so that it cannot be definitively attributed to one person.
Masking can also reduce identifiability by deleting or supressing certain values or data records. While masking can be effective when used alongside generalisation and suppression, it is not considered an anonymisation technique on its own.
What is generalisation?
Generalisation reduces the granularity or precision of the data by grouping or rounding it. Generalisation reduces the risk of people being singled out, as more of them are likely to share the same values. For example, a dataset containing the age of people can be changed so that only age bands are recorded (eg 20-30; 30-40).
What types of generalisation are there?
Generalisation can be achieved by reducing detail in the data’s variables, either across the whole dataset or within some parts of it.
Generalisation is a way to achieve K-anonymity, a method used to measure the identifiability of a dataset by determining how many people share the same set of attributes.
K-anonymity is a property of a dataset that ensures a person’s data cannot be singled out from other peoples’ data within the same dataset. It involves setting a threshold (k), and the goal is to prevent identification of people by grouping each record with at least (k-1) other records that share the same values for their attributes. The higher the value of (k), the stronger the privacy guarantees.
K-anonymisation is suitable for anonymising relatively static datasets with common groups of attributes. It is simple to implement without extensive technical resources or expertise, using suppression and generalisation methods.
K-anonymisation does have some limitations, for example, it can be:
- susceptible to certain types of inference attacks (eg homogeneity and background knowledge attacks). If an attacker knows that a person is within a certain group, they can discover other attributes they did not know to link to that group (such as a health condition); and
- weak for data with large numbers of variables containing personal data.
Example: K-anonymisation
The NHS’s standard for publishing health and social care data requires that, for strong anonymisation, k is set to five.
This means that for every record in the data set that describes the characteristics of a person, there are at least four other people also represented by records in the data set who share the same characteristics.
What is randomisation?
Randomisation can:
- remove the link between a person and the data, without losing the value in the data; or
- reduce the risk of data matching between data sets, unless other available data sets use the same randomised values.
Randomisation can be achieved by adding or removing values to certain data categories or altering the individual records but maintaining the overall statistical properties of the dataset.
Randomisation lowers the risk of an attacker determining something about someone, without changing the granularity of the data.
Synthetic data is a type of randomisation. It involves creating new data that keeps the statistical properties of the original data through the use of algorithms. Synthetic datasets aim to keep these properties without including the original data points.
What types of randomisation are there?
Noise addition involves adding random values either to a specific set of records or variables, or to the whole dataset. Noise addition can preserve the statistical properties of a dataset.
Noise addition is less effective if there are large differences between values, or there are some outliers. You may need to consult an expert to determine how much noise to add. For example, insufficient noise will mean the data is not anonymous, while large amounts of noise may make the data unusable.
You could add noise to prevent linking the data to a specific person by:
- adding noise to each record in a way that keeps the mean of the distribution unchanged;
- ensuring the amount of noise varies for each record; and
- combining noise with other techniques such as the removal of direct and indirect identifiers, if required.
Example
A fitness centre tracks members’ weights to tailor fitness programs and monitor progress. The centre decides to release anonymised statistics of members’ weight after they have completed six months of a fitness program. In order to anonymise the data, noise, drawn from a random distribution, is added to each weight. For example, a person’s weight is disclosed within a 5kg range of the original values. Small increases or decreases are made to the weight of each person, within the specified range.
Noise is applied in proportion with the scale of the original values, so that this process does not produce results that are highly skewed in comparison with the actual results. Adding or subtracting between 1kg and 5kg from the original weights may reduce the risk of identification to a sufficiently remote level. Varying the data by smaller amounts may in some cases risk singling people out.
Differential privacy is a method for measuring how much information is revealed about a person. While it is not an anonymisation technique as such, it allows you to determine how much noise to add to achieve a particular privacy guarantee (a formal mathematical guarantee about people’s indistinguishability).
Differential privacy alters the data in a dataset so that values are harder to reveal, such as direct or indirect identifiers of people. If you add an appropriate level of noise, then you can use it as a way to anonymise personal information for other purposes (eg generating high-level insights).
Permutation involves swapping or shuffling records in the data by switching values of variables across pairs of records. This approach aims to introduce uncertainty about whether records correspond to real data elements and increase the difficulty of identifying people by linking together different information about them.
Permutation allows you to retain the precise distribution of a variable in the anonymised database. Swapping can easily be reversed if the swapped variables are linked to each other.
Permutation may be unsuitable in cases where:
- the correlation between variables is important for the purpose you use the information for. Therefore, swapping is not a suitable method;
- you need to maintain correlations between that variable and other variables; and
- the swapped variables are linked to each other, as swapping can easily be reversed.
Example
A fitness centre tracks members’ weights to tailor fitness programs and monitor progress. The centre decides to release anonymised statistics of members’ weight after they have completed six months of a fitness program.
The weight values for different members are moved around, so that they no longer relate to other information about that person.
This is helpful if they need to retain the precise distribution of weight values in the anonymised database, but they do not need to maintain correlations between weight values and other information about people.
What is masking?
Masking involves identifying and removing direct identifiers that may single someone out. Direct identifiers can relate to a single person in all datasets (eg an email address or credit card number) or only be unique for some datasets.
The degree of masking applied to the data will depend on the use case. Deleting certain values or data records can help to prevent attacks that can link records back to people or to determine specific attributes of a record with a degree of certainty.
Masking alone is not considered an effective anonymisation technique. However, it can play a role when combined with generalisation and randomisation techniques.
Example: combining masking, generalisation and randomisation
A retail company intends to release anonymised data about its customers’ shopping patterns for market research purposes. The original dataset includes identifiable information including: customer ID, age, gender, postcode, and total spend per month.
| Customer code | Age | Gender | Postcode | Total spend per month (£) |
|---|---|---|---|---|
| A1B2C3 | 24 | M | SE7 5PX | 105 |
| D4E5F6 | 36 | F | ME21 9UU | 210 |
| G7H8I9 | 42 | M | B78 9JE | 315 |
| ... | ... | ... | ... | ... |
To anonymise this data, the company uses a combination of masking, generalisation, and randomisation techniques.
The company uses masking to completely remove the customer IDs and the last part of the postcode for each record and gender from the dataset. This helps prevent anyone from linking the data back to specific customers using knowledge of their specific location, ID or gender. But there is still a risk because the data contains specific ages and exact total spends for each person. To mitigate this risk the company also implements generalisation and randomisation to reduce the risk of identification to a sufficiently remote level.
The company replaces the exact ages with age ranges (eg 18-24, 25-34) and the postcodes with broader geographic areas with a minimum size population. This makes it harder to identify people based on their age or location.
The company adds a small amount of random noise to the total spend per month. This preserves the overall distribution and trends in the data, but makes it impossible to know the exact spend of any individual customer.
| Age Range | Area | Total Spend per Month (£) (noised) |
|---|---|---|
| 18-24 | Stockport | 112 |
| 25-34 | Wolverhampton | 204 |
| 35-44 | Canterbury | 305 |
| ... | ... | ... |
In this case, even if someone knows a particular person who shops at this retail company, they would not be able to determine with a sufficient degree of certainty that any specific entry in the dataset corresponds to this person.
What should we consider when choosing anonymisation techniques?
The anonymisation approach you choose will depend on the nature of the data and your purposes. In some cases, you can combine these methods to provide a more robust method. Using these methods does not guarantee you will achieve anonymisation: successful anonymisation depends on contextual factors.
What about anonymisation of qualitative data?
Much of the anonymised data you create, use and disclose is derived from administrative datasets that are essentially statistical in nature. However, the techniques you use to anonymise quantitative data are not generally applicable when seeking to anonymise qualitative data or unstructured data (eg the minutes of meetings, interview transcripts or video footage). You need different techniques to do this.
You could consider methods such as:
- removing direct and indirect identifiers from documents (eg names, email addresses and other information that relates to people);
- applying blurring or masking to video footage to disguise faces and other information that may identify someone;
- electronically disguising or re-recording audio material; and
- changing the details in a report (eg precise place names, precise dates)
Anonymising qualitative material can be time-consuming. It does not lend itself to bulk processing and can require careful human judgement to determine if people are still identifiable, based on the data and other information which may be linked to it.
Example: anonymisation of free text
A research group wants to release anonymised transcripts from interviews conducted for a study. The original dataset includes the names of interviewees, their responses, and the researcher’s questions and comments.
To anonymise this data, the research group performs:
- masking (suppression): all names and other directly identifiable information are removed from the transcripts (eg companies, birth dates, addresses);
- generalisation: specific potentially identifiable details in the responses are replaced with more general terms (eg ‘a place’ instead of the actual place name); and
- synthetic data generation: machine learning techniques learn the structure and topic distributions of the original transcripts, and generate synthetic text based on it.
Other resources
For detailed recommendations on appropriate technical solutions for different types of data release, read Statistical disclosure control by Hundepool, Anco, et al. (2012).
For more information on k-anonymisation:
- the Anonymisation Decision-Making Framework, which provides further guidance on the use of k-anonymisation techniques.
- the NHS anonymisation standard for publishing health and social care data (ISB1523) NHS anonymisation standard for publishing health and social care data (ISB1523) ()
For more information on differential privacy and synthetic data, read our guidance on PETs.
For more information on anonymising qualitative data, including images and text, read Anonymising qualitative data by the UK Data service.
NIST SP 800-226 Guidelines for Evaluating Differential Privacy Guarantees describes techniques for achieving differential privacy and their properties, and covers important related concerns for deployments of differential privacy.